Researchers are turning more and more to high-content imaging for
help with drug discovery, clinical trials, dosing strategies, and
studies of cellular interactions and functions. And 3-D imaging could
take these applications even further.
Although not yet king, high-content imaging
is increasingly important in the life sciences. By allowing the use of cells as
the basic unit in rapid and highly parallel biological research, high-content imaging
also is helping scientists increase their understanding of how cells function and
interact.
“It’s really about being able to have more in-depth
answers to biological questions,” said Mark A. Collins, director of marketing
for cell science at Thermo Fischer Scientific Inc.’s Cellomics division in
Pittsburgh.
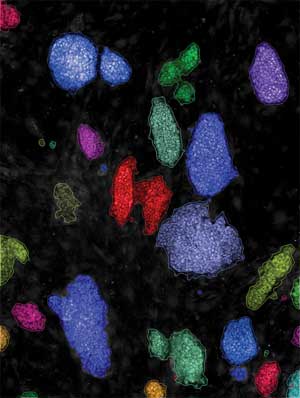
Using machine learning, PhenoLOGIC™ software classifies cells in high-content images. Courtesy of PerkinElmer.
Thanks to advances in photonics, algorithms, probes and automation,
researchers can now generate and analyze reams of image data. On the horizon is
the ability to do so in three dimensions, in combination with spectroscopy, or in
other ways to tease out even more information.
Currently, high-content imaging is done on the organelles inside
cells, cells themselves, tissues and complete organisms like zebra fish or Caenorhabditis
elegans. In all cases, imaging of a great many items is done, with a variety of
parameters captured in an automated fashion. It’s not unusual for an assay
to generate hundreds of thousands of numeric values and images.
Hence, everything depends upon the quality and reproducibility
of the image. Better imaging starts with better lighting. For instance, there have
been advances so that LEDs can now replace filters and white-light sources, Collins
said.
Since its introduction late in 2009 by Thermo Fisher, most customers
have taken the LED option, he added. Among the benefits are the elimination of bulb
changes, very stable illumination and the ability to dial the intensity up or down
as needed. The latter allows the light to be set so that cells are not disturbed
or damaged, a particularly important consideration in extended live cell assays.
LEDs also may make it possible to control illumination on a color basis or even
for each location in a 96- or 384-well plate.
Data from high-content screening has to be mined for knowledge.
For example, Collins pointed to the company’s recently introduced assay for
predictive liver toxicity testing.
Drugs under development that fail often do so because they injure
the liver. Using high-content imaging to detect five or six biomarkers of damage
enables a better than 90 percent accurate toxicity prediction, he said. Doing this
early in product development could save a drug company hundreds of millions of dollars
a year, and it can do so while potentially replacing animals with cell-based alternatives.
“It’s a hardware, software and wetware, or reagents,
platform designed to do toxicity assays. You might consider it to be a virtual lab
rat,” Collins said of the product. He added that this and other customized
systems are lower in cost and complexity than general-purpose high-content imaging
systems.
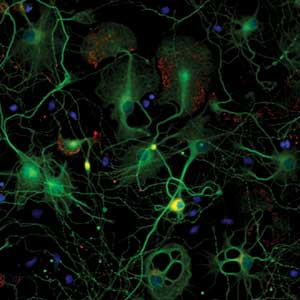
Synapses from primary rat cortical cultures acquired on Thermo Scientific
Arrayscan VTI HCS. ©Thermo Fisher Scientific.
Waltham, Mass.-based PerkinElmer Inc. also has put photonic advances
to use. Jacob G. Tesdorpf, the company’s director of high-content instruments
and applications, noted that the latest cameras offer 14-bit resolution over relatively
large fields of view, making it possible to acquire finer gradations of data over
a wider area.
A challenge confronting vendors is increased multiplexing, with
today’s standard being three to four channels. Investigators, however, would
like to go to as many as six, which may require the development of new fluorescent
reporters. For multiplexing, the signal from fluorophores should overlap as little
as possible.
What’s more, it is best if the fluorescence is in the red
or near-infrared. Longer wavelength excitation and emission decreases light-induced
cellular damage, a plus when cell vitality may influence important biomarkers. Longer
wavelengths also penetrate cells and tissues more easily, leading to better images.
Fluorescent probe development is, therefore, an active area.
But software advances may be as, or even more, important, Tesdorpf
said. Scientists using high-content imaging are typically life sciences experts.
They know how to grow cells, tissues and animals and how to classify them into groups.
Generally, they want tools that can handle complex image analysis without requiring
software expert knowledge. PerkinElmer has made it easier for users of its high-content
imaging systems to accomplish this.
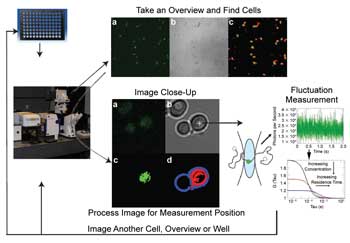
Researchers combine high-content imaging with fluorescence correlation spectroscopy (fluctuation measurement right) to track protein interactions and diffusion within a cell. Courtesy of Winfried Wiegraebe, Stowers Institute for Medical Research.
“Basically, the user defines a training set by pointing
and clicking. The software applies machine learning to it and then is able to classify
cells from a whole set of images,” Tesdorpf said.
He noted that dealing with the amount of data generated by high-content
imaging is an area where ongoing improvement is needed. In that, the field benefits
from progress being made elsewhere. Suitable statistical methods and associated
software algorithms may be one way to handle the mountain of data.
The quantity of data could be going up, courtesy in part to efforts
of researchers around the world. For instance, a team from the Stowers Institute
for Medical Research in Kansas City, Mo., has developed high-content screening based
on fluorescence correlation spectroscopy, which previously had been done manually.
The researchers automated the process, cutting the time to interrogate
a cell from 10 or so minutes down to 10 seconds. They used transmitted light to
determine cell boundaries, segmented the cell into sections via software, then followed
the fluctuating fluorescence in the cell. The correlation statistics allowed them
to measure protein interactions, diffusion properties and local concentrations in
cells in a 96-well plate, and their custom setup enabled them to do this in an automated
fashion.
In a February 2011 SPIE proceedings paper, the researchers reported
that they had measured the local concentration and diffusion properties of 4000
different proteins in yeast. Team leader Winfried Wiegraebe, head of microscopy
at Stowers, said that this proof of feasibility will be followed by additional research
aimed at addressing biologically important questions.
“At this moment, we are using the diffusion data to learn
about diffusion properties of differently sized proteins in different cell compartments,”
he said.
As for commercial prospects, the system is based on a modified
Zeiss platform. Thus, a product using the technique is possible.
In another example, software could boost the amount of data produced
by high-content screening, doing so by a process of machine learning. Researchers
at the European Molecular Biology Laboratory (EMBL) in Heidelberg, Germany, have
developed software that they named Micropilot.
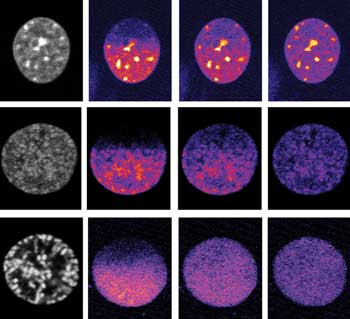
Software is rendering high-content imaging easier and more useful. Here, automated selection of an interphase (top left) or prophase (early, middle left, and late, bottom left)
cell is done with a trained classifier. Time lapse images after fluorophore labeling
follow (second left to right). Courtesy of Christian Conrad, European Molecular
Biology Laboratory. Reprinted from Nature Methods.
The software includes a classifier that sorts objects into groups,
said Christian Conrad, senior scientific officer at the EMBL’s Advanced Light
Microscopy Facility. It does so using a training set of roughly 50 to 100 objects
per class and uses techniques that make it relatively insensitive to noninformative
object features.
“The design of Micropilot is such that it does not matter
which images are fed into the classification. The features suit mostly cell-based
applications; however, it requires that the cells be segmented as objects on a cellular
or subcellular level,” Conrad said.
The software has been used in various applications, including
quantifying microtubule dynamics, as described by Sironi et al in the March 2011
issue of Cytoskeleton. Micropilot, or software based on it, could soon be showing
up in commercial systems. Several companies are collaborating with EMBL staff to
facilitate this, Conrad reported.
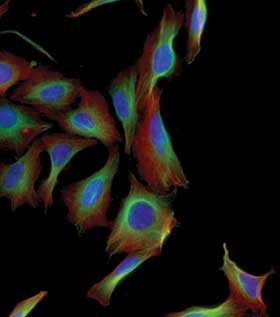
Cytoskeleton of HeLa cells acquired on the Thermo Scientific CellInsight personal image cytometer. ©Thermo Fisher Scientific.
Finally, high-content imaging is about to take on a new dimension.
Cell cultures today are largely 2-D affairs, with cells and imaging confined to
a plane. In natural settings, however, cells live and grow in 3-D structures, with
differences in cell shape and function dependent upon location in X, Y and Z. To
truly represent a larger organ or animal, a cellular assay and the associated high-content
imaging has to take the third dimension into account.
The first steps in this direction are under way. For example,
Thierry Dorval, cellular differentiation team leader at Institut Pasteur Korea in
Seongnam, leads a group developing generalized software and a hardware platform
for the task. The work is a joint effort between computer scientists and biologists.
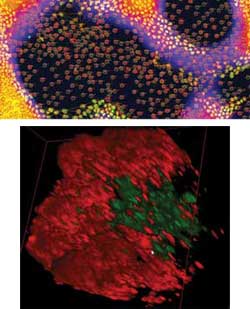
High-content imaging in 3-D starts with data acquisition, here of an embryonic body (top), with green indicating cell nuclei and red stemness. Then image processing software allows extraction of cellular phenotype at the level of the cell population (bottom). Courtesy
of Thierry Dorval, Institut Pasteur Korea.
To be useful in a high-content setting, the software algorithms
must be robust and efficient. That’s the only way to handle artifacts, reduce
errors and still deal with the hundreds of thousands of images generated, Dorval
said.
Currently, software to make the process of extracting and analyzing
3-D high-content data easy and effective doesn’t exist. In a July 2010 Journal
of Biomolecular Screening paper, Dorval and others published results from what he
characterized as 2.5-D software, a partial solution to the problem. The group quantified
the shape, texture and fluorescence intensity of multiple stained subcellular structures,
including the nucleus, the Golgi apparatus and the centrioles.
One goal of the software project is to recognize observable characteristics
at the cellular level. Another is to do such phenotype extraction one level up,
at the level of the structure itself.
In justifying this 3-D high-content imaging objective, Dorval
said, “This is not only one cell. This is the cell that is surrounded by others.
So how do the others influence the cell?”