For tasks such as singulation, in which bulk mixed items are separated for sorting and routing, deep convolution neural networks have boosted efficiency to >99%.
DAVID BRUCE, FANUC AMERICA CORP.
Vision-guided robotics (VGR) is one of the largest-growing sectors in both the robotics and machine vision markets. While industrial robots are used in a variety of industries, the ability to guide a robot based on information from a machine vision system is enabling industrial
robots to be used in many more
applications and industries.

A parcel induction cell using Plus One Robotics’ PickOne system. Courtesy of Plus One Robotics.
Modern industrial robots are incredibly repeatable machines, with the largest payload robots (250 to 500 kg) achieving repeatability of fractions of a millimeter, and the smallest payload robots (5 to 70 kg) achieving micron-level
repeatability. These high levels of repeatability have enabled the widespread adoption of industrial robots. However, taking full advantage of a robot’s repeatability requires a lot of engineering time and expertise to successfully integrate a process and ensure that the equipment the robot interacts with is extremely rigid.
Today, the increasing use of machine vision to locate parts in 2D or 3D and to communicate location information to
the robot significantly reduces systems
engineering requirements, and the
entire process becomes orders of magnitude simpler and cheaper. In fact, some current robot applications would not be possible without the use of
machine vision guidance.
Vision-guided robotics emerged in the late 1980s, with expansion occurring in the last 20 years as the price
and performance of machine vision systems dramatically improved and software interfaces for both robots
and vision systems became easier to use. The techniques used to locate parts and detect faulty ones are
based on discrete or rules-based
analysis of 2D and/or 3D data.
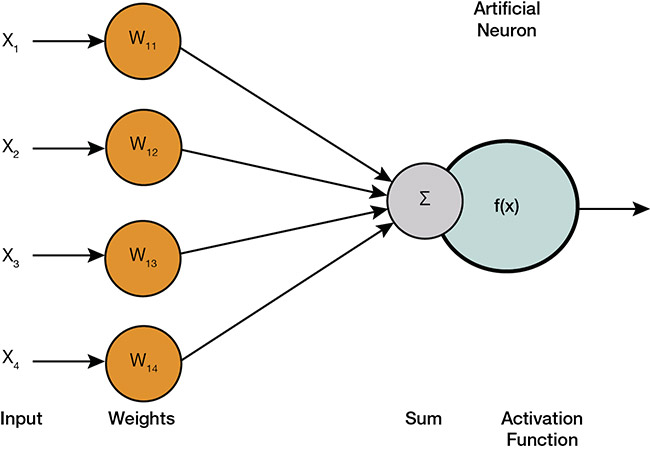
A diagram depicts how inputs determine whether an artificial neuron will fire. Courtesy of CC BY 0.
Although these rules-based techniques are sometimes referred to as traditional machine vision, and they are powerful and increasingly easier to apply, they do not work well in cases involving a wide variety of parts or scenes with varied lighting. Depending on the complexity of the setup, a VGR system using traditional machine vision will require a significant amount of programming and debugging by a knowledgeable machine vision engineer and robot programmer.
Artificial neural networks 101
The term “artificial neural network” was inspired by the idea that a machine can be constructed to mimic the way the human brain works. Our limited understanding of the human brain includes the knowledge that it contains about 80 billion neurons, each connected to 1000-plus other neurons, yielding a neural network with trillions of interconnections. Depending on the aggregate electrical signal from all these connections, a neuron will either fire, transmitting its own electrical signal to some or all of its connections, or not fire, sending no electrical signal to its connections. Very little is understood about how this biological neural network yields experiences such as eating chocolate or seeing a loved one’s face, or how it enables a human to catch a baseball or a frisbee. Perhaps building an artificial neural network containing as many neurons and connections as the human brain could lead to the emergence of human-like intelligence, which is what computer scientists have been working toward since the mid-1950s. Advancements in computer hardware over the last 10 years, in particular the graphical processing unit (GPU), have enabled the development of artificial neural networks containing trillions of connections that are very proficient in natural language processing, game play, and image recognition.
An artificial neuron can be thought of as a node that accepts many different inputs from many other nodes. Each input is a number, each input number is multiplied by a unique weight, and the results of these multiplications are added up to a bias. The final resultant number will be used to decide whether the node (the artificial neuron) will fire, sending some modified version of the resultant number to the other neurons that it is connected to deeper in the network, or it will not fire, sending zero to the other neurons it is connected to. The tuning or training of an artificial neural network is the process of deciding what the many weights and biases should be. For large neural networks, the number of weights and biases, often called the parameters, can exceed 1 billion.
Increasing contextual information
In image analysis that uses a fully connected neural network, all the pixel values from a digital image are converted into a large one-dimensional vector and connected to the first layer of a multilayered neural network. Each layer of the fully connected neural network will have a configurable number of neurons, each fully connected to the next layer. The last layer is the decision layer, where the number of neurons will equal the number of desired outputs. The neuron with the highest value in the decision layer will represent the decision of the neural network. Using a fully connected neural network for image analysis does not produce great results, but if the image is inputted as regions of 3 × 3 or 4 × 4 pixels, or N ×
N pixels, the results are much better. This type of neural network is called a convolutional neural network (CNN) because the process of inputting the
N × N regions is called a convolution. It is thought that the reason CNNs work better than fully connected neural networks is because the local information contained in the local regions is maintained. Going deeper into the layers of a deep CNN, the regions are compared with each other. This increases contextual information from basic building blocks such as edges or lines to more complicated structures until the final layer, where the decision is made to classify the image — for example, as a horse, cat, boat, box, and so on.
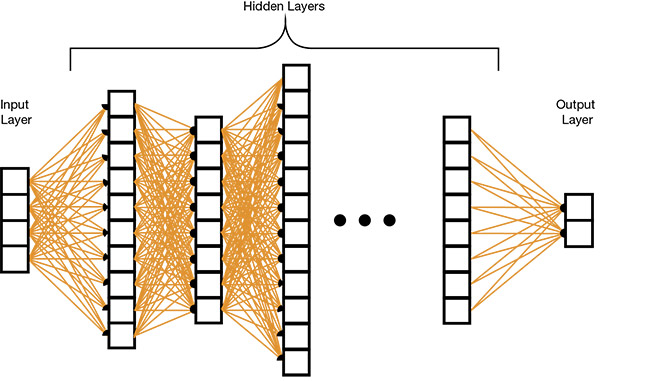
A multilayer, fully connected neural network. Courtesy of Wikimedia.
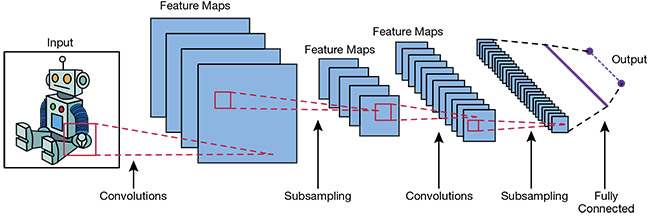
A deep convolutional neural network (DCNN). Courtesy of Wikimedia.
Deep convolutional neural networks (DCNNs) rely solely on supervised learning and require massive amounts of manually labeled images to yield a DCNN model that will deliver good results. Neural networks, whether
consisting of many fully connected layers or many convolutional layers, work in a forward direction (sometimes referred to as inference), and in a backward direction when the learning is accomplished based on images with known objects in them. The inference pass is very quick, on the order of
milliseconds, depending on the hardware used. A backward (or learning) phase will take several hours to many days depending on the size of the
neural network. GPUs, which are very fast at parallel processing multiplications and additions, can greatly
accelerate both inference and backward propagation.
AI for logistics singulation
The logistics industry is a growth area for vision-guided robotics. Simple singulation is a manual task in which bulk mixed items are separated into single items and then introduced into a highly automated system that handles the rest of the sorting and routing (if there is only one item per skid, tray, or bot, etc.). The bulk items could be
different-size packages, consumer items, or boxes, and the speeds necessary to justify a system’s return on investment varies per application from 500 to 1500 singulated items per hour. Modern industrial robots can achieve these speeds, but traditional machine vision techniques cannot. Given the required rates of production, it is crucial that the robot can properly acquire a single item each cycle. This will depend on how well the vision system can segment the scene and provide the best position for the robot to pick from. Traditional machine vision techniques can be 80% to 95% successful at segmentation, based on the application and items. The vision system doesn’t recognize the different items, but it can discern the boundaries between items and pick a single position at which a suction cup or parallel gripper would work well at extracting an item. Modern DCNNs have proved to be >99% effective at segmentation for these tasks. While the difference between 95% and 99% may seem inconsequential, consider what it means for a required throughput of 1500 items per hour. At 95% successful segmentation, there will be 75 items not properly segmented each hour, and at 99.5%, there will be seven items not properly segmented. Each time an item is not properly segmented, downtime will vary from a few seconds to several minutes.
For robotic automation to be feasible for singulation tasks in the logistics
industry, a vision system with the highest possible segmentation is required.
Efficient parcel induction
Plus One Robotics provides machine vision software to enable industrial robots to perform singulation tasks in the logistics industry. The company uses DCNNs for segmentation of a wide variety of packages, boxes, and small consumer goods, utilizing a wide variety of 3D sensors that provide a
2D RGB image and a 3D point cloud. The DCNN accepts the 2D RGB image and provides a segmented region
for the part in pixel space, which is
then combined with the point cloud information to yield a 3D position and orientation. This information is then transmitted to an industrial robot that picks the package.
Shaun Edwards, chief technology officer at Plus One Robotics, said he experienced the superior segmentation abilities of DCNNs during the development of one of Plus One’s parcel induction applications, when a DCNN model was able to very quickly segment two white envelopes shingled on each other — something traditional machine vision was not able to reliably accomplish.
“This experience convinced me that an AI approach for real-world applications is not only possible, but, for certain applications, absolutely necessary,” he said.
Plus One also offers a service that securely contacts a “human-in-the-loop” when confidence in the AI model is low. This person can log into the system and highlight on a 2D image where the next pick location should be, and he or she can simultaneously connect to several different systems at various locations.
Plus One currently installs systems that start out with 80% autonomous operation. Production moves to 100%, however, after the human operator guides the system through the 20% of packages that the AI model has low confidence in, Edwards said.
To ensure success, automation integrators and end users need to understand the limitations and the requirements of each technique when deploying AI.
The AI model can be improved based on the operator’s actions, which provide ground truth data that can be used to retrain the model.
“This approach allows a system to
go from 80% to 99% autonomous
production in a matter of weeks rather than months, and production is still 100% from day one, with throughput improving as the model improves,” Edwards said.
Being able to improve an AI model based on manually labeled data directly from the operation is key to realizing the true power of any AI-based automation. This improvement does not happen in real time and currently requires experts in the AI model to carefully retrain it with the new ground truth data and test the new model with old and new data to ensure improved performance. This retraining requires a powerful computer with one or more GPUs, and it will
take anywhere from several hours to several days to accomplish, depending on the complexity of the AI model used.
The use of AI in manufacturing is still at an early stage. And although its potential to reduce engineering hours and automate more tasks is very real, the potential for irrational exuberance and misapplication of AI techniques also exists. To ensure success, automation integrators and end users need to understand the limitations and the requirements of each technique when deploying AI.
Meet the author
David Bruce is engineering manager at FANUC America Corp. in the General Industries and Automotive Segment, where he oversees engineers who support FANUC robot integrators and end users using iRVision and third-party machine vision-enabled applications. He has a bachelor’s degree in electrical engineering from the University of Windsor in Ontario, Canada, and a master’s degree in computer science from Oakland University in Auburn Hills, Mich.; email: [email protected].
AI Makes Quick Work of Seat Belt Assembly Inspection
2D vision-guided robotic applications require the vision system to report part location in only two dimensions. If a part has two or more stable resting positions, the 2D machine vision system may also need to distinguish which 3D orientation the part is in — whether the part is upside-down or right-side up — as well as its 2D location. Depending on the geometry of the part, determining which side is up may be very difficult with 2D machine vision. This kind of determination often needs to be made in automotive parts inspection.
“[There] was an automotive application involving handling part of a seatbelt assembly from a flex feeder, and it was very difficult to know which side was up using the 2D image,” said Josh Person, a staff engineer in FANUC America Corp.’s General Industries and
Automotive Segment.
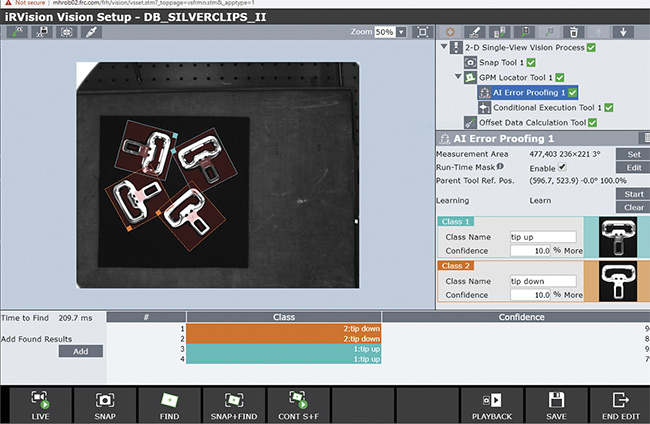
FANUC iRVision’s AI error-proofing tool inspects parts using machine learning technology. Courtesy of FANUC.
FANUC offers an AI error-proofing tool as part of its iRVision system that uses a machine learning algorithm to perform binary classification. The tool works by allowing the user to manually classify several different images as either Class 1 or Class 2, and then the machine learning will adjust all the parameters in an AI model to provide proper classification at run time.
When executing the AI error-proofing
function, the tool will output the detected class (1 or 2) and a confidence level for the decision. The acceptable confidence level can be adjusted. When a result from the AI error-proofing tool provides an incorrect classification, or a correct classification with a low confidence level, the user can manually add the image to the database with its proper classification,
and the machine learning will execute again, improving the model.

A FANUC robot employs the company’s iRVision system for bin picking. Courtesy of FANUC.
|