With the help of new user-friendly tools such as heat maps, vision system operators have greater control in distinguishing good samples from bad — making deep learning more effective for inspection tasks.
BRUNO MÉNARD AND YVON BOUCHARD, TELEDYNE DALSA
The manufacturing industry is being turned on its head as AI and deep learning transform the way goods are manufactured and inspected. The combination of software, new deep learning techniques, the power of parallel processing, and easy-to-use tools is at the core of this transformation.

While traditional image-processing software relies on task-specific algorithms, deep learning software uses a multilayer network that implements pretrained or user-trained algorithms to recognize good and bad images or regions. Traditionally, hundreds or even thousands of high-quality, properly classified images were required to train the system and create a model that classifies objects with a high level of predictability. Just gathering this type of data set has proven to be an obstacle, hindering deep learning adoption by mainstream manufacturing.
New technological advancements are making it easier for manufacturers to embrace deep learning as part of the inspection process. Today, developers
train deep learning systems using fewer bad images or even none. While deep learning software for machine vision has been around for more than a decade, it is now becoming more user-friendly and practical. As a result, manufacturers are moving from experimenting with deep learning software to implementing it.
No two loaves alike
Deep learning is ideal for tasks that are difficult to achieve with traditional image processing methods. Deep learning is especially suited when many variables are involved, such as lighting, noise, shape, color, and texture. For example, in food inspection, no two loaves of bread are exactly alike. Each loaf has the same ingredients, and each weighs the same amount, but the shape, color, and texture may vary slightly and still be within a range of normality. Another example is determining the ripeness of an apple; several factors determine whether an apple is ripe, including color, softness, and texture. It is with these types of evaluations that deep learning shines. Other examples include inspecting surface finish quality, confirming the presence of multiple items in a kit, and detecting foreign objects, all to ensure quality throughout the assembly process.
A practical example that shows the strength of deep learning is defect inspection on textured surfaces. Figure 1 illustrates a plate of brushed metal with scratches. Some of these scratches are less bright, and their contrast is in the same order of magnitude as that of the textured background itself. Traditional techniques usually fail to capture these types of defects reliably, especially when the shape, brightness, and contrast vary from sample to sample.

Figure 1. Scratches on brushed metal. Traditional inspection techniques usually fail to capture these types
of defects reliably. Courtesy of Teledyne DALSA.
Defect inspection can also involve the classification of a textured surface as being good or bad. Figure 2 shows a semiconductor die surrounded by a glue seal (the textured border); the seal needs inspection for correctness. The image shows a good seal with the proper texture density and brightness. Traditional methods would require a lot of effort (tuning) to classify this seal, while deep learning can do it easily.

Figure 2. Textured seal inspection. Deep learning can easily perform this inspection. Courtesy of Teledyne DALSA.
Simple classification
Despite the advantage of deep learning over traditional image processing techniques, challenges exist. First, many users lack the understanding of the requirements to achieve success with deep learning. Second, until recently, deep learning required a huge data set to train a system. Many system users have not been able to take advantage of deep learning due to lack of high-quality, properly classified images. In cases where a large data set is available, the next challenge is labeling each image. This labeling can be a daunting
task because it has to be done by an expert and needs to be error-free. When a large number of classes (different groups with a unique label for each) are involved, errors become likely.
Subtle labeling errors are one reason for failure to reach satisfactory performance from AI tools. It is painful to realize the amount of wasted time involved in failures due to bad labeling in the original data set. A proper data set is the most important item in a particular system and is usually treated as proprietary intellectual property by the user.
Some scratches are less bright, and their contrast is in the same order of magnitude as that of the textured background itself. Traditional techniques usually fail to locate these types of defects reliably, especially when the shape, brightness, and contrast vary from sample to sample.
While typical deep learning applications require hundreds or even thousands of image samples, in more challenging or custom applications, the training model may require up to a million or more image samples. Even with enough images, users need to ensure they have the right mix of “good” and “bad” images to meet the parameters of the training model. To achieve the expected results from the training model, a balanced data set is required. This type of training that uses both good and bad examples is called defect detection and is considered a simple classifier.
To verify whether the training model is accurate, it must be tested with a new set of images. When the model achieves close to the training set model, it is said that the model generalized well. When the model does poorly on the test set, this tends to reflect that the model remembers all training cases and has not learned what makes an image good or bad. This is known as overtraining or overfitting. When the test set does better than the training set, then the training set is suspect (perhaps due to a poor distribution), or the test set is too small. This is known as supervised learning.
Anomaly detection
Some applications have only good examples with which to train a network. In many production environments, users know what is acceptable but can never be sure of all possible scenarios that could cause rejects. There are cases where there is a continuous event of unique new rejects that can occur at very low rates but are still not acceptable. In the past, these types of applications could not deploy deep learning effectively due to the lack of bad examples. This is no longer true. New tools have enabled manufacturers to expand the applications that benefit from deep learning.
Anomaly detection is a new technique for classification that uses only good examples to train a network; the network recognizes what is considered normal and identifies anything outside that data set as abnormal. This is called unsupervised learning.
A “good example” data set on a graph would look like a blob. Anything that falls within the blob classifies as normal, and anything that falls outside the blob classifies as abnormal — or an anomaly. When the system detects an anomaly, an operator decides whether the anomaly is an acceptable variation. The operator will want to understand why the system rejected the image. To help with that, new user-friendly tools, such as heat maps, are used to pinpoint the anomaly and visually show the problem. A heat map is a pseudo-color image that highlights the pixels at the location of the defect (Figure 3).

Figure 3. Two defects highlighted with heat maps, which are used to pinpoint the anomaly and visually show the problem. Courtesy of Teledyne DALSA.
In some cases, the operator will see the rejected image and immediately understand why it was rejected. In other cases, the image may be rejected because of the way it was cropped, or if the network is looking at the wrong spot because the network has not been trained enough. This information helps the operator determine whether the image is an acceptable variation and helps to speed up the training process.
Anomaly detection tools are available today and can be added to a normal data set, enabling the expansion of deep learning into new applications that could not take advantage of its benefits previously. The inclusion of anomaly detection helps to reduce engineering efforts needed to train a system. If they have the data, nonexperts in image processing can train systems while reducing costs significantly.
Good vs. bad samples
Whether using a simple classifier or an anomaly detection algorithm for implementing defect detection in manufacturing environments, users must train the neural network with a minimal set of samples. As mentioned previously, anomaly detection allows an unbalanced data set, typically including
many more good samples than bad ones. But regardless of how balanced, these samples need to be labeled as good or bad and fed into the neural network trainer. Graphical user interface (GUI)-based training tools are an easy way to feed data sets to the neural network while allowing the user to label images graphically.
Figure 4 illustrates a training session
where all samples are listed. For each sample, the “Label class” column specifies what the corresponding image should be (i.e., good or bad). The user enters this information at training time. One easy way to automate this tedious process is to put the samples in two different folders — good and bad, and use the folder names as labels. Also important when training a data set is to reserve a portion of the samples for testing. One good rule of practice is to allocate 80% of the data set for training, while leaving the remaining 20% for testing as the train/data set ratio percentage. When the training samples pass through the neural network, the weights of the network adjust for a certain number of iterations, called epochs. Unlike training samples, testing samples are passed through the neural network for testing purposes without affecting the weights of the network. Training and testing groups of samples are important to develop a proper training model that will perform well in production.
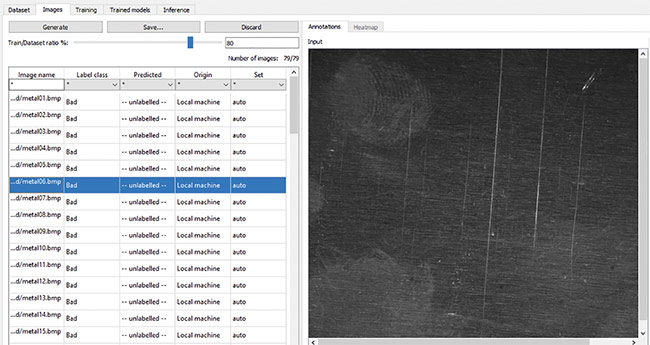
Figure 4. Training and labeling. ‘Good’ and ‘bad’ folders help automate the process. Courtesy of Teledyne DALSA.
Once the training set is created and labeled, the training process can begin. Training parameters are called hyperparameters, as opposed to parameters, which are the actual weights of the neural network. Model hyperparameters are the properties of training data that the model will learn on its own and that govern the entire training process. Most common hyperparameters include the learning rate, which tells the algorithm how fast to converge to a solution; the number of epochs, which determines the number of iterations during the training process; the batch size, which selects how many samples are processed at a time; and the model architecture that is selected to solve
the problem. A common example of mode architecture for a simple classification is ResNet, which is a convolutional neural network, a frequently used model architecture in classification problems such as defect detection.
Once hyperparameters are configured, the training process is ready to be launched. Training time ranges from tens of minutes to tens of hours and is dependent on the number of samples in the data set, the hyperparameters, and the power of the GPU card. During training, two basic metrics need monitoring: loss function and accuracy. The loss function shows the difference between current model prediction (which is the output of neural network) and expectation (the ground truth, i.e., what is versus what should be). This loss function should go toward zero while training. If it diverges, users may have to cancel training and restart it with different parameters. The accuracy reveals how well a model compares to a prediction sample. This metric should lean toward 100% during training. In practice, users will rarely achieve 100% but often between 95% and 99%. Figure 5 depicts these two metrics after the network was trained on 300 samples.
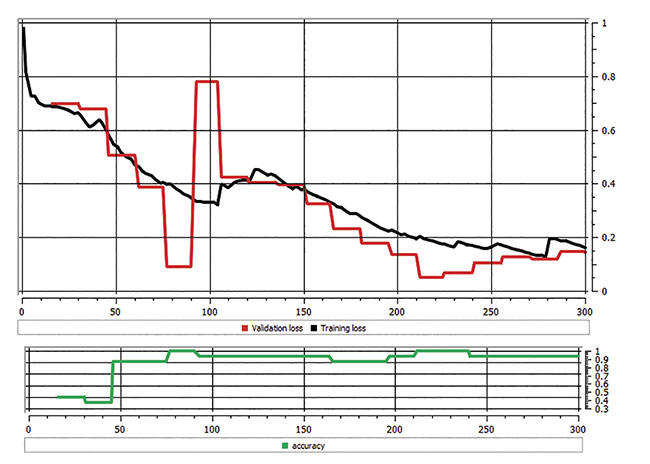
Figure 5. A chart showing loss of function and accuracy. Courtesy of Teledyne DALSA.
After training is complete with acceptable accuracy, the model is ready to use in production; applying a model to real samples is called “inference.” Inference can be implemented on a PC using GPU cards or on an embedded device using a parallel processing engine. Depending on the size, weight, and power (SWAP) required by the application, various solutions are available for implementing deep learning inference — such as CPUs, GPUs, and DPUs (deep-learning processing units) — whether running on ASIC or field-programmable gate array (FPGA) types of devices.
Deep learning is more user-friendly and practical than ever before, enabling more applications to derive the benefits. Deep learning software has improved to the point that it can classify images better than any traditional algorithm — and may soon be able to outperform human inspectors.
Meet the authors
Bruno Ménard is a software program manager in the Smart Products
Division at Teledyne DALSA; email: [email protected].
Yvon Bouchard is the director of technology for Asia Pacific at Teledyne
DALSA; email: yvon.bouchard@
teledyne.com.