
CMU, Fujitsu Team Up for Dynamic 3D Structure Representation
PITTSBURGH, July 11, 2023 — Researchers from Carnegie Mellon University (CMU) and Fujitsu have developed a method to convert 2D images to a 3D structure. The researchers’ Dynamic Light Field Network (DyLiN) method handles nonrigid deformations and topological changes and surpasses the current static light-field networks.
According to lead researcher Laszlo Jeni from the CUBE Lab in the CMU School of Computer Science, creating a 3D structure with 2D images requires deep understanding of how to handle deformations and changes. The DyLiN approach harnesses AI to address this long-standing bottleneck, improving over existing methods in terms of terms of speed and visual fidelity, Jeni said.
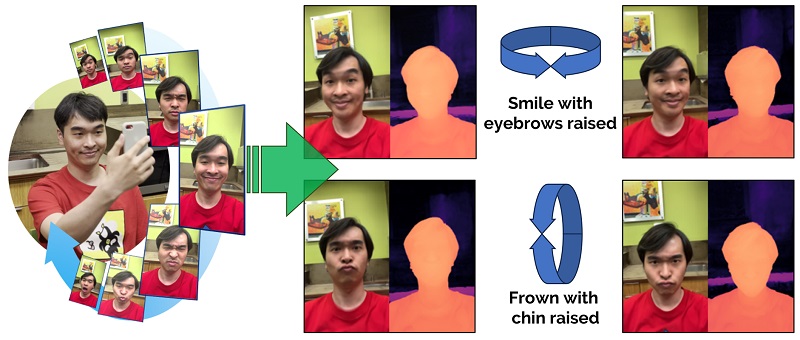
Dynamic Light Field Network (DyLiN) accommodates dynamic scene deformations, such as in avatar animation, where facial expressions can be used as controllable input attributes. Courtesy of Carnegie Mellon University.
DyLiN learns a deformation field from input rays to canonical rays and lifts them into a higher dimensional space to handle discontinuities. The team also introduced CoDyLiN, which enhances DyLiN with controllable attribute inputs. Both models were trained via knowledge distillation from pretrained dynamic radiance fields.
During testing, DyLiN exhibited superior performance on both synthetic and real-world data sets containing various nonrigid deformations. DyLiN matched state-of-the-art methods in terms of visual fidelity while being 25× to 71× faster computationally. When tested on attribute-annotated data, CoDyLiN surpassed its teacher model.
“The strides made by DyLiN and CoDyLiN mark an exciting progression toward real-time volumetric rendering and animation,” Jeni said. The improvement in speed, without sacrificing fidelity, opens opportunities in various applications, he said. The research, supported by Fujitsu Research America, specifically represents advancements in 3D modeling and rendering. The implementation of these methodologies is therefore poised to benefit industries that heavily rely on deformable 3D models, including virtual simulation and augmented reality. For example, DyLiN and CoDyLiN can create a 3D avatar from actual images, enabling the transfer of facial expressions from a real person to their virtual counterpart.
The research team presented its work at the Conference on Vision and Pattern Recognition (www.doi.org/10.48550/arXiv.2303.14243).
/Buyers_Guide/Fujitsu_Optical_Components_Ltd/c33092