AI can achieve much higher and more robust recognition rates for defects, keeping flawed products from continuing in the production cycle.
JOHANNES HILTNER, MVTEC SOFTWARE GmbH
As processes become highly automated and universally networked within the Industrial Internet of Things (IIoT), digitization is fundamentally changing industrial production. The production routine at manufacturing companies involves various machines and robots that perform an increasing number of tasks along the industrial value chain. While stationary robots have become commonplace in assembly halls over the past 20 years, a new generation of compact and mobile robots are integral to production workflows today. Collaborative robots, or cobots, frequently work alongside their human counterparts on the assembly floor. These collaborators complement each other, carrying out individual, perfectly coordinated process steps consecutively, and even handing off workpieces to each other.

Machine vision contributes to universally networked and highly automated processes in the Industrial Internet of Things (IIoT). Courtesy of MVTec Software GmbH.
Modern accompanying technologies are used to make these highly automated scenarios safer and more efficient. Machine vision plays a key role here because it is capable of precisely recognizing a wide range of objects in the production run, based on optical features alone. Image acquisition devices such as cameras, scanners, and 3D sensors record the workflow from different perspectives. This results in large amounts of digital image data that are processed by machine vision software and made available for various tasks. As the “eye of production,” the technology seamlessly monitors the scenarios, reliably identifies objects, and precisely determines workpiece positions. Machine vision also makes it possible to accurately detect and automatically remove defective products before they enter the rest of the production cycle, thus playing a pivotal role in quality assurance.
AI analysis
In the context of IIoT processes, artificial intelligence (AI) is being increasingly used in machine vision solutions. Typically, hundreds of thousands of images are generated, forming a solid database that can be evaluated in detail with the aid of AI. A variety of machine learning and especially deep learning methods, along with convolutional neural networks (CNNs), are used for this purpose.
Integrated into modern machine vision software, AI technologies can achieve much higher and more robust recognition rates for applications that include electronics and food, as well
as automotive and semiconductor fabrication. In-depth analysis of the image data makes it possible to clearly categorize the objects to be identified and, based on a training process, assign them to classes. This process involves automatically training special features that are typical for the particular class. As a result of the training, the images of the objects to be detected are labeled according to class. The models, or classifiers, trained in this way can then assign newly recorded images to the classes already trained.
In addition to unequivocally identifying and classifying objects, this approach also allows the reliable detection and precise location of defects in manufactured products, be they electronic boards, metal parts, or foods. Deep learning algorithms also optimize the results in a company’s quality management system. For example, AI allows a pharmaceutical manufacturer to detect a wide variety of defects, such as cracks and scratches, in a large number of pills that vary in shape, size, texture, and color. The special advantage that this new approach has over conventional machine vision functions is that deep learning dramatically reduces the effort involved in detecting errors.
Product defects vary a great deal in appearance; the many different types of damage — such as scratches, cracks, or dents — can take on many different shapes and sizes. It would
be almost impossible to manually program algorithms that could clearly recognize all conceivable errors based on sample images, because this would require hundreds of thousands of images, all of which would have to be analyzed individually. And then algorithms would still have to be developed that could describe any defect in detail. Clearly, such a time-consuming method would be very difficult to put into practice.
Deep learning makes this process significantly less labor-intensive by introducing the ability to independently learn certain error features and thereby precisely define the particular problem classes. A wide range of error types, such as in the inspection of pills mentioned earlier, can thus be trained and reliably detected. Deep learning also minimizes error quotas, which can be as high as 10 percent with manual programming. They drop to nearly zero when self-learning algorithms are used.
Deep learning networks
One option for manufacturers is to develop their own deep learning networks. This, too, is extremely labor-intensive. Several hundreds of thousands of sample images are needed to achieve valid recognition results. For example, it took MVTec engineers between six and 12 months to develop a highly optimized pretrained deep learning network. After all, objects can be unequivocally identified only if various parameters — such as color, shape, texture, and surface structure — are incorporated. Experienced developers would be required to professionally configure
the networks. Another challenge is that many sample images are protected by licenses and can therefore be used only with the consent of the originator. Moreover, purchased images are unsuitable for training if they show nonindustrial motifs. Companies must consider all of these challenges if they want to create deep learning networks of their own.
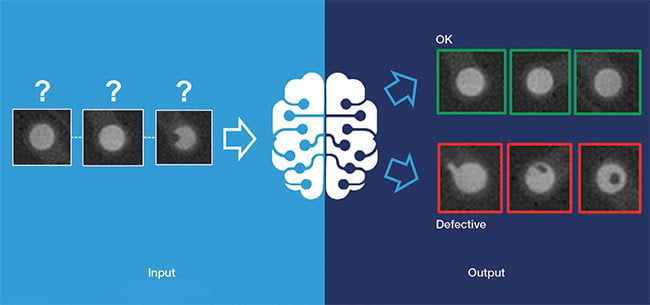
Thanks to self-learned object models, deep learning networks are able to assign newly added image data to the appropriate classes. Courtesy of MVTec Software GmbH.
A more practicable approach is to acquire and use pretrained networks, such as those from MVTec, that have already learned the basics of how to extract general information from images. The pretrained network learns how to use these generic image features on a specific application in order to distinguish between classes of objects, features, or errors. Software is available that comes with extensively pretrained deep learning networks already integrated. These networks have been trained with license-free images that have industrial themes (for example, metal parts or images from the food industry), which means customers may use these pretrained networks without limitation. Typically, pretrained deep learning networks require only 300 to 500 sample images instead of hundreds of thousands for each error class, which makes it easier for companies to provide a sufficient number of relevant training images. Also, the subsequent training takes only a few hours and achieves a much higher recognition rate than when defect classes are programmed manually. The biggest advantage of pretrained networks is that they significantly reduce the user’s workload.
According to estimates by industry experts, a company would need to invest between six and 12 person-months to create its own network from scratch. An investment in commercial off-the-shelf standard software means that the extensive knowledge of deep learning specialists is already included.
Tailor-made training
Dedicated vision software may also contain advanced functions that enable companies to train their own networks with very little effort. The software integrates pretrained networks that are optimized in terms of speed or maximum recognition rates, for example. This enables companies to create professional CNNs that precisely match their requirements. They can classify new image data and reduce programming; only a basic level of machine vision expertise is required in-house.
Not only can deep learning algorithms be used to train models of physical objects but they can also reliably recognize letters and numbers in machine vision applications by analyzing large amounts of digital image data.
Not only can deep learning algorithms be used to train models of physical objects but they can also reliably recognize letters and numbers in machine vision applications by analyzing large amounts of digital image data. This makes the technology an attractive choice for optical character recognition (OCR). OCR systems generate detailed raster graphics that visualize the text down to the last pixel, based on digital image information. The integrated software reads out the graphics, recognizes certain character combinations that they contain, and even combines them into words or entire sentences, if needed. Industrial application scenarios in particular impose strict demands on character recognition. For example, an alphabetic or numeric code is printed on products to clearly identify and classify them within the entire flow of goods. Under harsh industrial conditions, this text can be difficult to read because the individual characters are often distorted, unclear, or displayed at an angle.
Modern machine vision software with integrated deep learning functions is able to reliably recognize these types of character codes; an OCR classifier based on deep learning algorithms allows the user to benefit from a large number of pretrained fonts. Thus, this software can achieve much higher recognition and reading rates than any other classification method. In particular, dot-print, SEMI, industrial, and document-based font types can be reliably read with a single universal pretrained font, making it unnecessary to select a particular pretrained font for each type of application. Companies can thus significantly reduce workload and save a great deal of time. In extensive test series, the optimized character recognition process has even been shown to cut the error rate in half in images with many different characters of varying sizes, shapes, font types, and qualities. Products can thus be identified more reliably based on the printed character code, which optimizes the entire industrial flow of goods.
Embedded vision systems
Embedded systems are one more key application for machine vision technologies. Compact devices with embedded software are widespread, particularly in IIoT environments. These devices include smart cameras, vision sensors, smartphones, tablets, and handhelds. They play an important role in today’s networked and highly automated IIoT processes. An important next step is to equip embedded systems with powerful deep-learning-based machine vision software that is able to run on embedded boards based on the popular NVIDIA Pascal architecture, paving the way for multiple use cases of deep learning technology on a large variety of embedded devices.
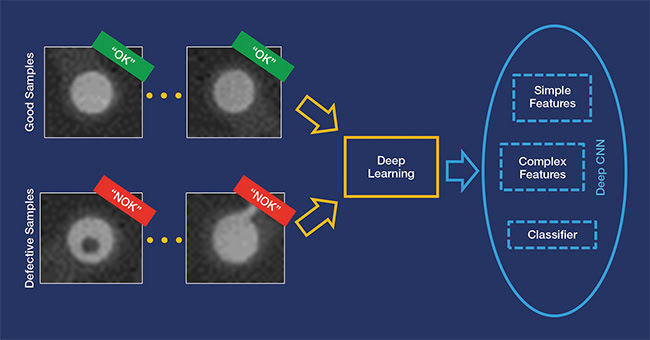
Deep learning technologies and convolutional neural networks (CNNs) can learn and distinguish between defects. Courtesy of MVTec Software GmbH.
The IIoT is characterized by highly automated and universally networked production flows. Machine vision is becoming increasingly important as a key technology in this context. It can be used to reliably identify a wide range of objects in the flow of goods within factories and thus provide data for the rest of the process chain. Innovative machine learning and deep learning technologies can help streamline these automated processes by ensuring even more robust recognition. As a result, companies benefit from a higher degree of automation and much greater productivity.
Meet the author
Johannes Hiltner is product manager
at MVTec Software GmbH. He is responsible for the product HALCON; email: [email protected].